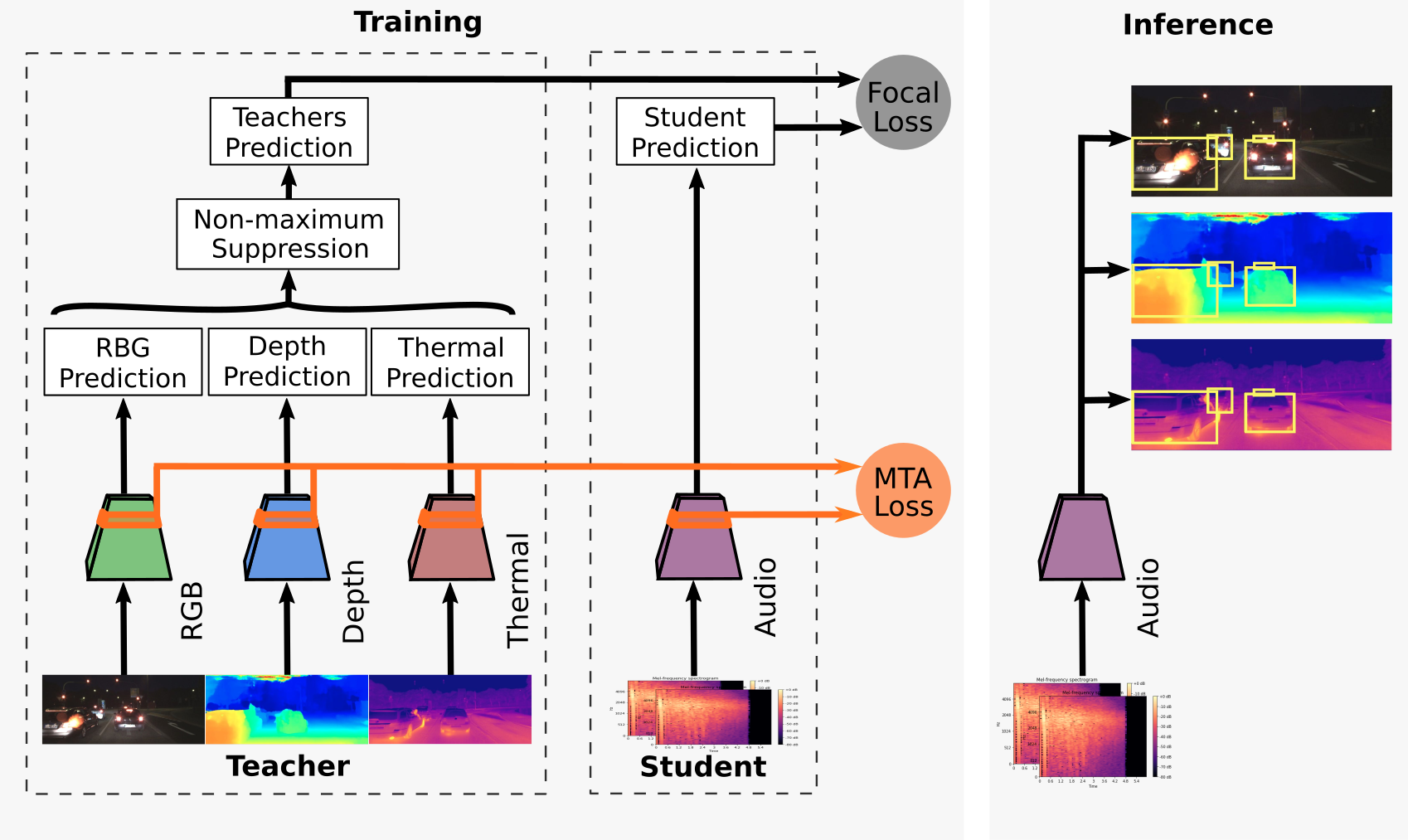
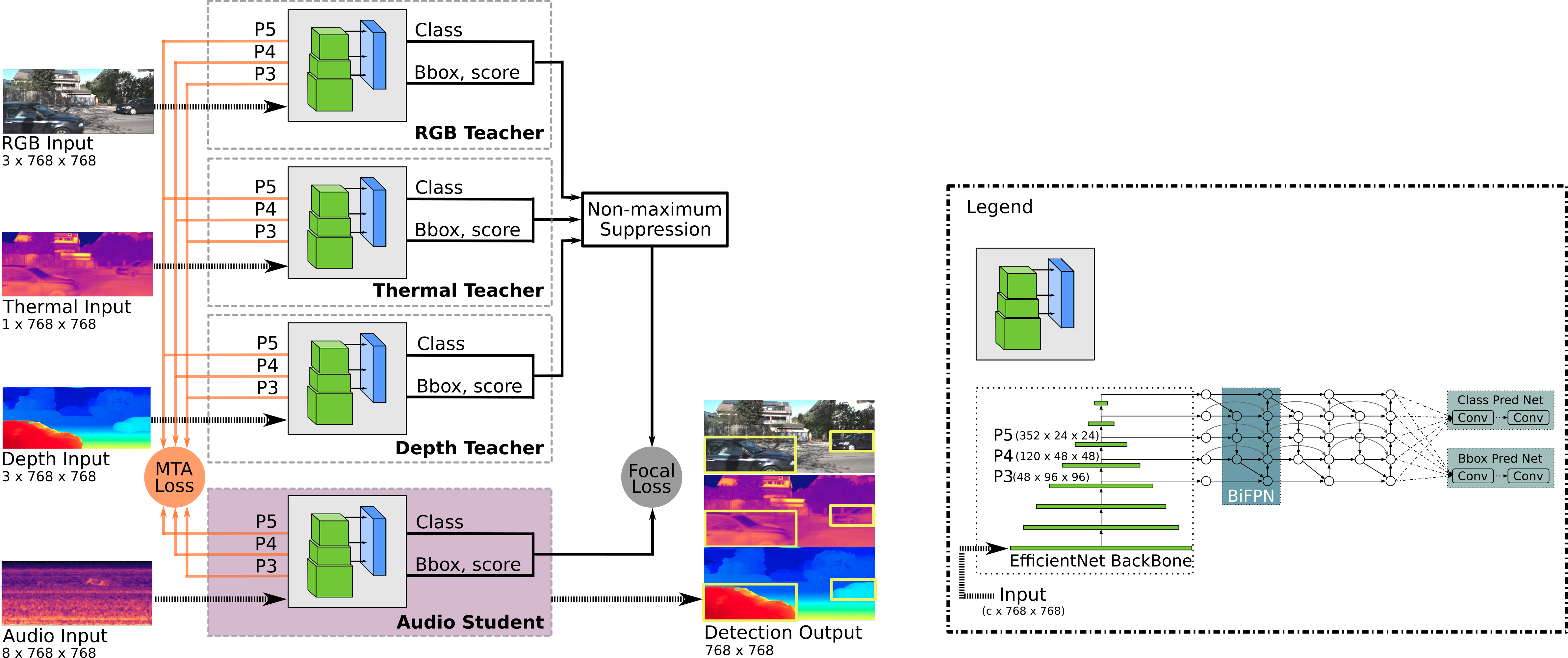
Our framework consists of multiple teacher networks, each of which takes a specific modality as input, for which we use RGB, depth, and thermal to maximize the complementary cues that we can exploit (appearance, geometry, reflectance). Each of these modalities has its own benefits and drawbacks. RGB images perform better in well-illuminated conditions but poorly in the night-time, whereas thermal images perform better in low illumination conditions. Depth images help discern multiple objects better than RGB or thermal images. Our framework can be used with other modalities such as LiDAR or RADAR that may improve the performance in conditions where RGB, depth, and thermal fail.
The teachers are first individually trained on diverse pre-existing datasets to predict bounding boxes in their respective modalities. We then train the audio student network to learn the mapping of sounds from a microphone array to bounding box coordinates of the combined teachers' prediction, only on unlabeled videos. To do this, we present the novel Multi-Teacher Alignment (MTA) loss to simultaneously exploit complementary cues and distill object detection knowledge from multimodal teachers into the audio student network in a self-supervised manner. During inference, the audio student network detects and tracks objects in the visual frame using only sound as an input. Additionally, we present a self-supervised pretext task for initializing the audio student network in order to not rely on labor-intensive manual annotations and to accelerate training.
To facilitate this work, we collected a large-scale driving dataset with over 113,000 time-synchronized frames of RGB, depth, thermal, and multi-channel audio modalities. We present extensive experimental results comparing the performance of our proposed MM-DistillNet with existing methods as well as baseline approaches, which shows that it substantially outperforms the state-of-the-art. More importantly, for the first time, we demonstrate the capability to detect and track objects in the visual frame, from only using sound as an input, without any meta-data and even while moving in the environment. We also present detailed ablation studies that highlight the novelty of the contributions that we make.